A Perspective on Birds Eye View (BEV) Networks
If you’ve been following advancements in 3D perception for autonomous driving, you’ve likely come across Bird’s Eye View (BEV) networks. But what are they? There are many different approaches these days, but to put it simply, a BEV network is a type of deep learning model that takes in sensor input, such as images from a camera, and outputs a representation of the scene from a top-down perspective. They’re becoming a go-to method for enhancing how self-driving cars “see” the world.
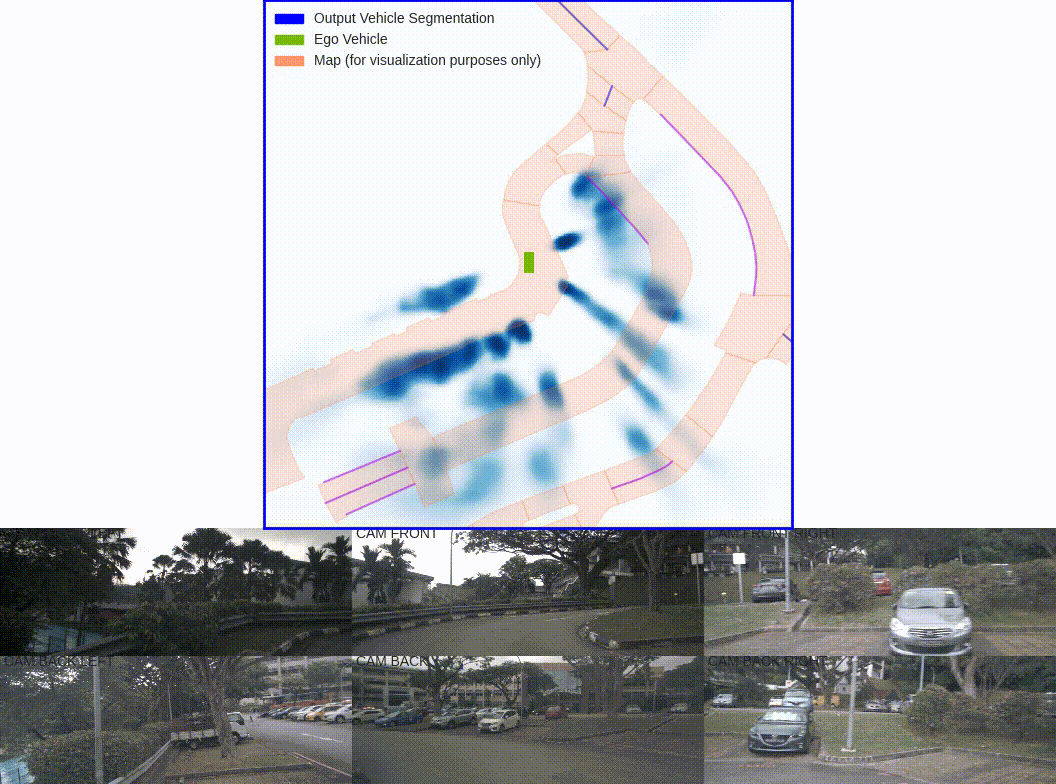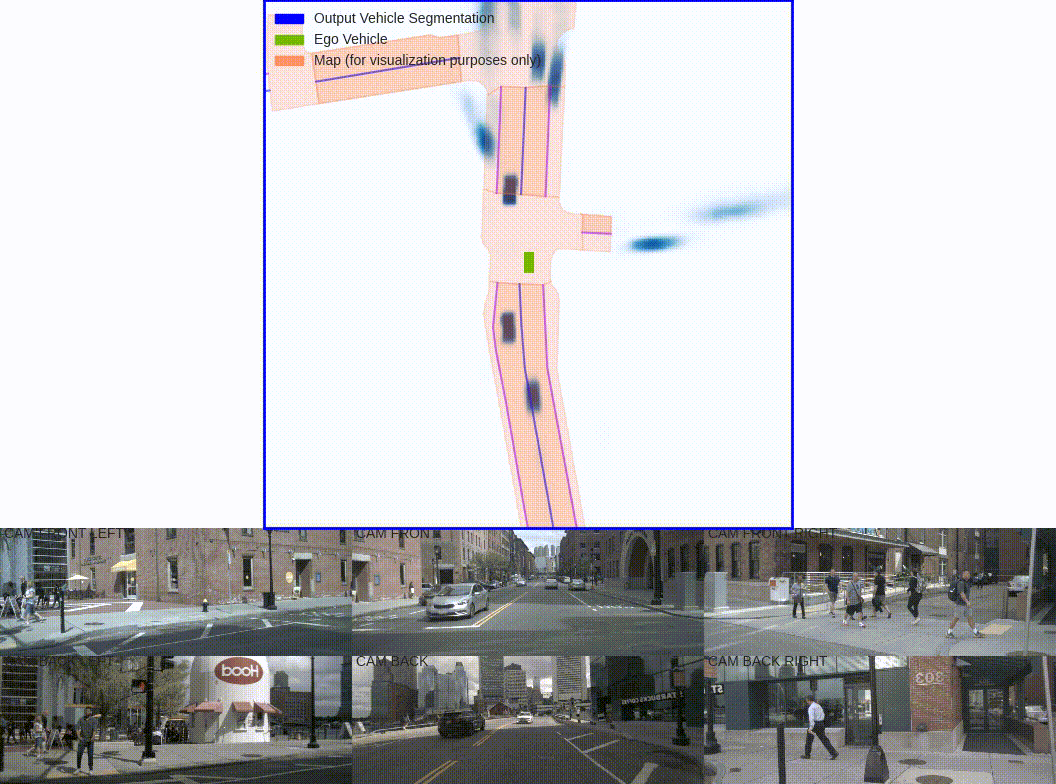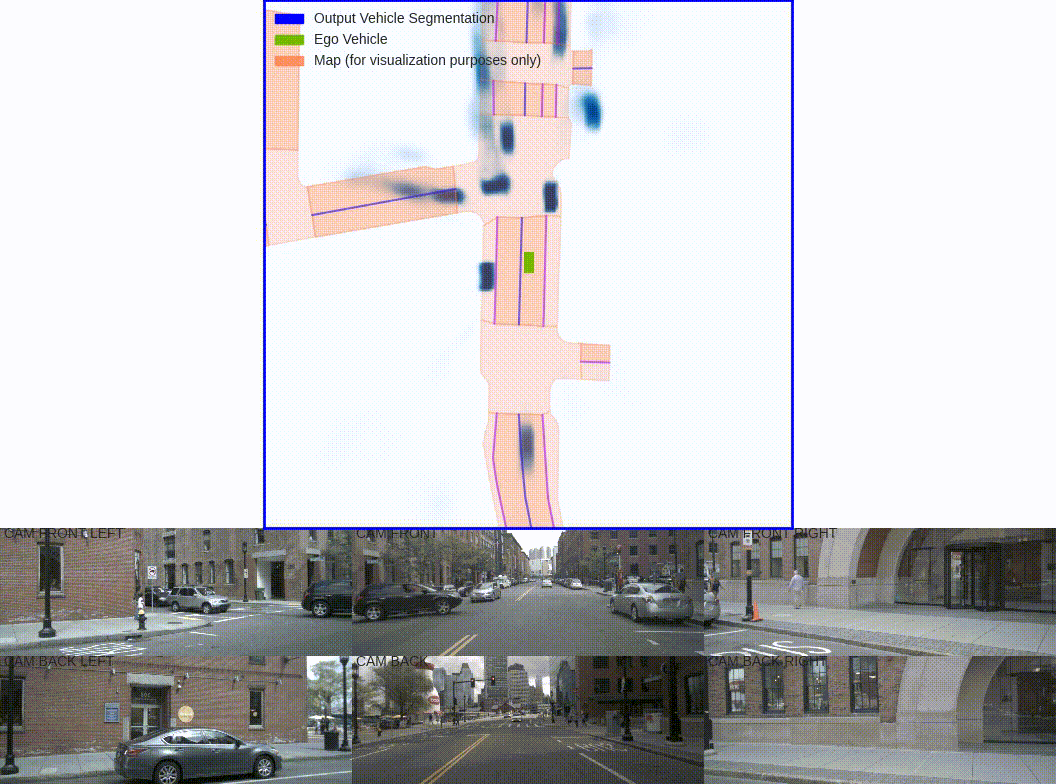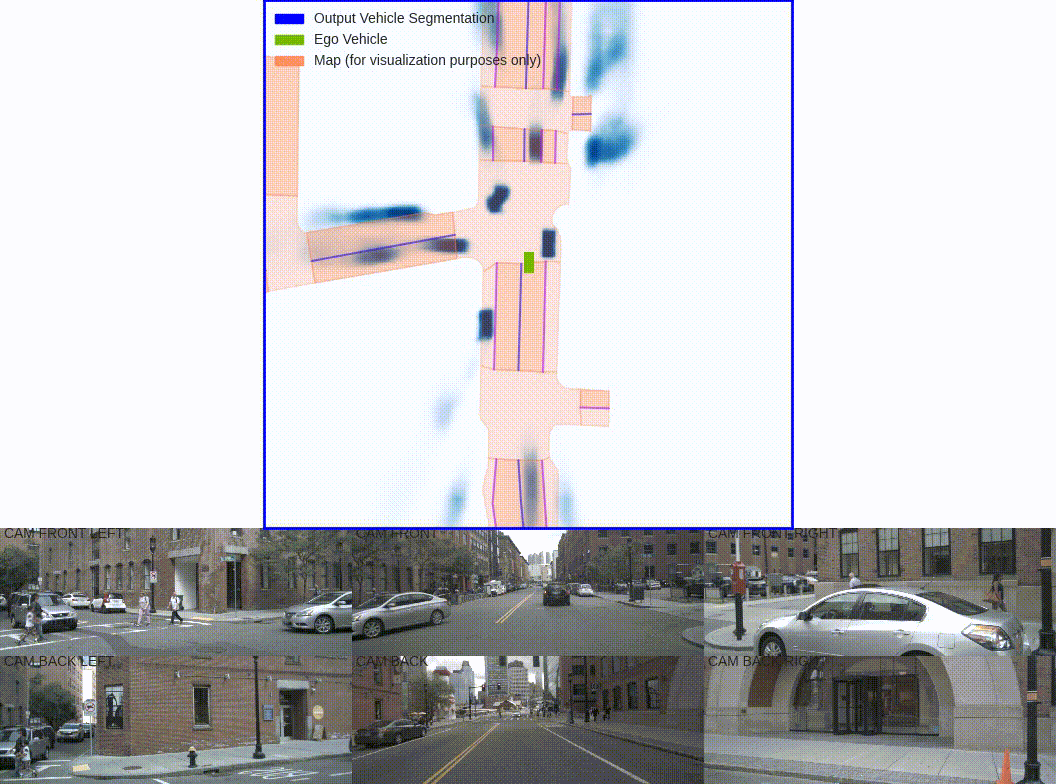
Shown above is one of the pioneering papers in this space, Lift-Splat-Shoot. Using inputs from six cameras of around the driving vehicle, this BEV network is able to generate a single unified representation of the surrounding vehicles.
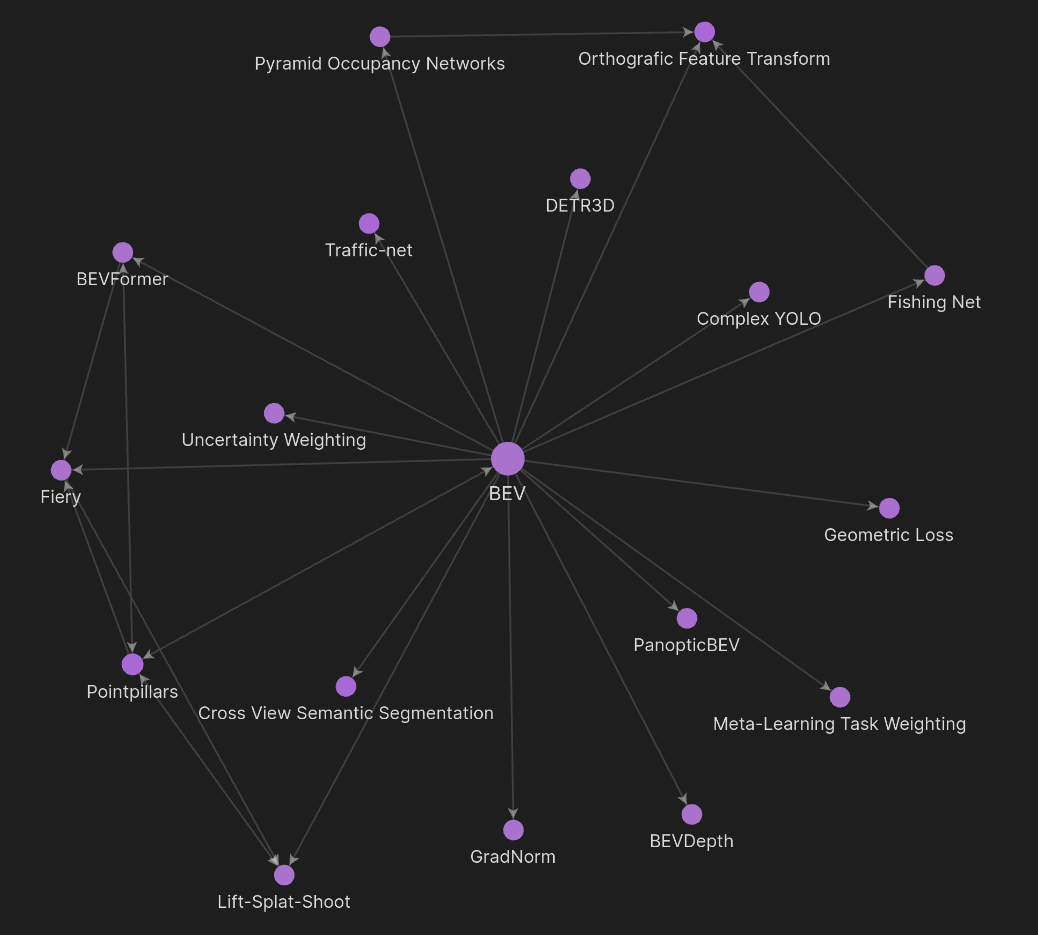
Above was my personal journey exploring the BEV research space, created with Obsidian. In this article we explore such BEV applications, their architectures, and how they fit in modern and upcoming autonomous stacks.
Motivation to Understand The BEV Landscape
Evolution of the Autonomous Vehicle Stack
Landing on the scene in the late 1980s, classical methods like Canny edge detection and homography-based techniques were key components of early autonomous driving systems, helping to identify lane boundaries and transform camera perspectives for better road understanding. Over time, these classical techniques were modularly replaced by deep learning-based systems, as modern CNN-based object detection and segmentation networks showed promising results in the early perception pipelines and naturally evolved into to the state of the art Birds Eye View networks, which offer more accurate and robust top-down scene interpretation directly from multi-sensor data.
In their paper Reimagining an Autonomus Vehicle, researchers from Wayve show an indicative vision of where traditional rule-based autonomy stacks and their evolution to end-to-end architectures.
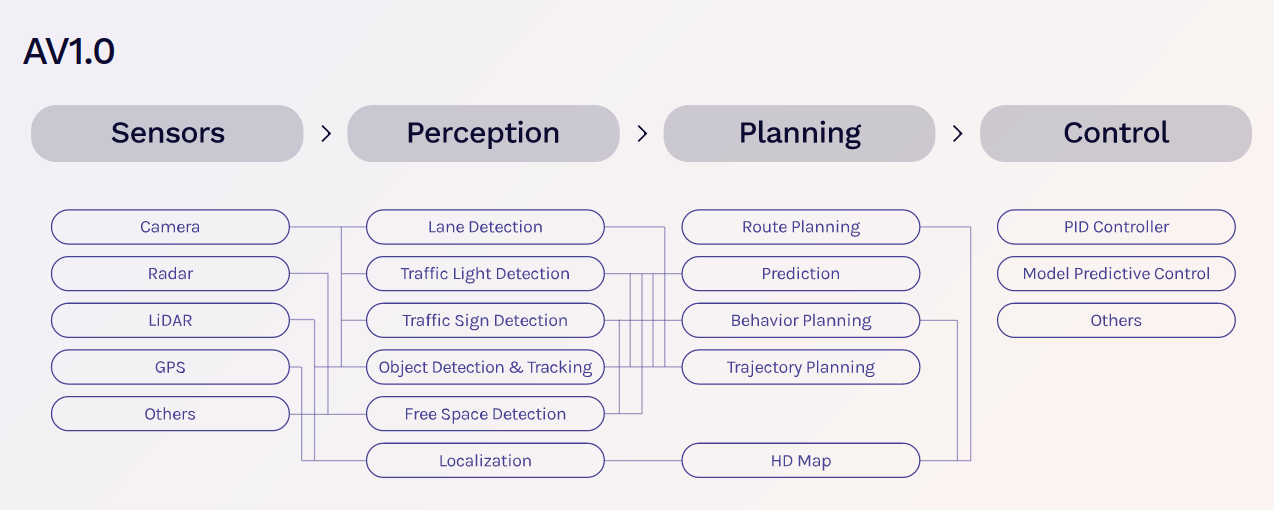
Shown above is what is considered the modern or traditional autonomous stack, consisting of Perception, Planning, and Control. Which Wayve terms AV1.0. The perception pipeline takes the raw sensor input from the various sources, and feeds them through various scene understanding pipelines, which are then fed to planning pipelines to assemble into path-planning tasks and are sent to controls for actuation commands. Wayve makes their case that these traditional hand-coded architectures have merit, but are ultimately brittle and prone to flaws and edge case gaps when faced with the goal of achieving true autonomous driving.
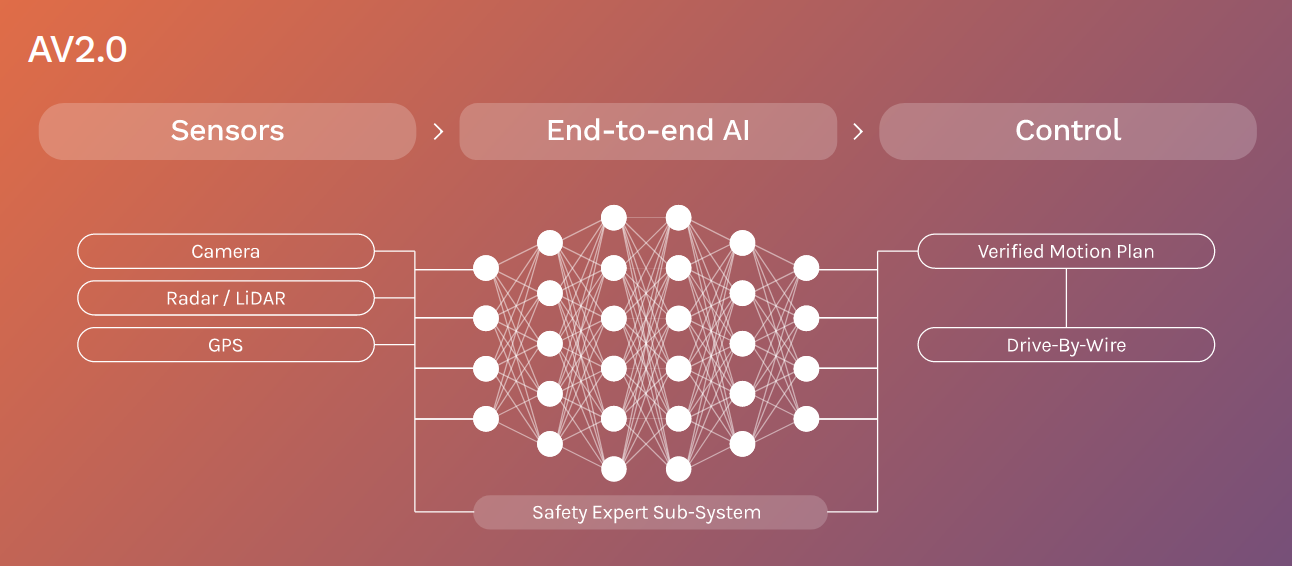
This AV2.0 architecture takes the processed sensor input directly into an end to end network to generate a motion plan for the controller to follow. Wayve proposes this architecture, positing that the autonomous driving future will-be be completely data-driven, and that having this system would lend itself to a clean and robust learning pipeline that is generalizable to different vehicles.
Where BEV fits
Bird’s Eye View networks can fit into both AV1.0 and AV2.0 stacks, sitting at the perception portion of the stack since the nature BEV directly works with multi-sensor features.
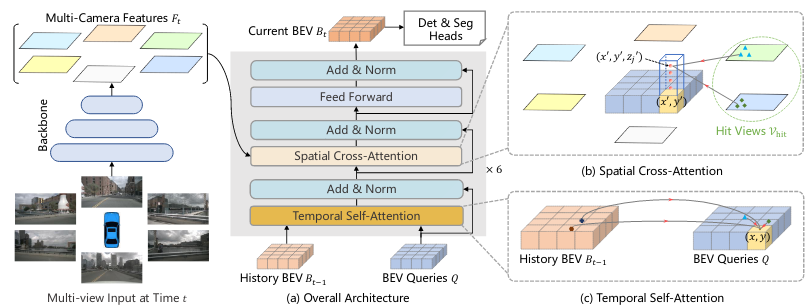
Above is an example of the original BEVFormer architecture. In this paper, the authors train the network to perform segmentation and 3D object detection, which are some outputs of the perception pipeline in AV1.0.
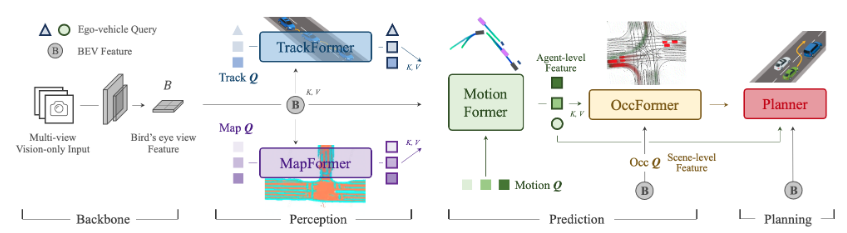
A powerful illustration of BEV in AV2.0 comes from the winning paper of CVPR 2023, UniAD, focuses on the end-to-end architecture. The authors integrate the BEVFormer as the backbone of their End-to-End architecture, which provides a unified basis for downstream processing.
What makes BEV so attractive? My favorite techincal explanation comes from the lift, splat, shoot authors:
- Translation Equivariance: Shift an image, and the output shifts along with it. Fully convolutional single- image object detectors roughly have this property and the BEV Nets inherit this from them.
- Permutation Invariance: The camera order doesn’t matter; the results are the same.
- Ego-Frame Isometry Equivariance: No matter where the camera is placed, it’ll detect the same objects in the ego frame.
By preserving these properties and being fully end-to-end differentiable, BEV networks streamline the perception process.
Lifting Strategies
Overview
The lifting strategy is the process of transforming 2D image features and other sensing inputs from a perspective view (PV) into a bird's eye view (BEV) representation. These strategies can be thought of as the core mechanism of BEV methodologies.
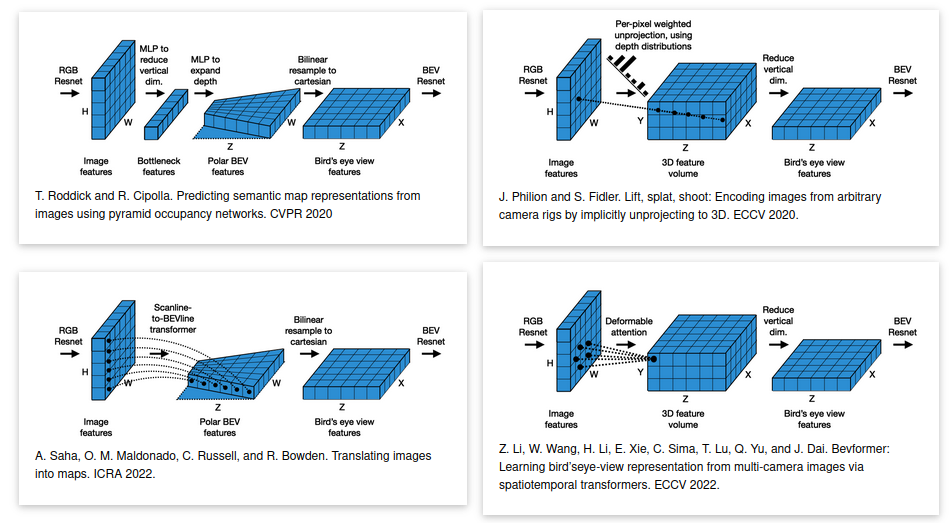
Shown above is an illustration of popular approaches to transforming perspective view (PV) images into bird's eye view (BEV) representations. The four quadrants demonstrate (clockwise from top-left):
| Category | Architecture |
|---|---|
| MLP-Based | Pyramid Occupancy Networks |
| Depth-Based | Lift-Splat-Shoot |
| Transformer-Based (Scanline) | Image2Map |
| Transformer-Based (Deformable Attention) | BEVFormer |
It's a good idea to establish the flow before diving into the details. Each approach uses what is called a backbone. This backbone, or encoder, is generally a fully convolutional neural network (CNN) that takes in an image and outputs a feature map that are passed to the lifting strategies. Once these features are translated into the unified BEV space, the network may then feed these BEV features into a single, or set of task heads to produce the final predictions.
Strategies Breakdown
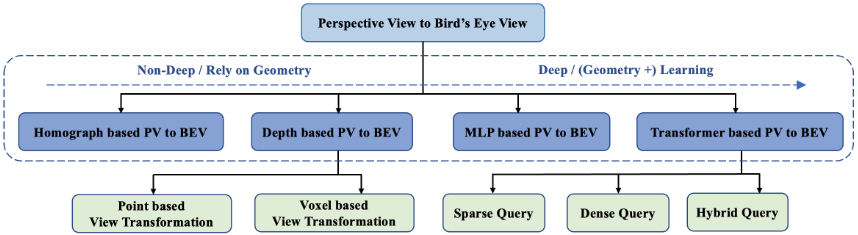
I really like how this survey paper breaks it down. Following their topology, we will go through the big four fom left to right.
Geometric-Based PV2BEV
- Homography-Based: Also known as Inverse Perspective Mapping. This concept has actually existed since the 90s, and applications of this traditionally haven't used neural networks. Homography applies simple geometric transformations to the sensor intrinsics and extrinsics to get a BEV-like view. This falls within the traditional realm of robotics algorithms and has been extensively used in perception pipelines. However, this technique falls short due to the assumption that the ground is flat, which can be inadequate in more demanding automated driving applications.
- Depth-Based: These networks use geometric priors such sensor intrinsics and extrinsics to extract depth from image features using deep learning techniques, enabling them to project sensor data into 3D space and then to a BEV plane. Starting in 2019 with single image detection, depth networks have seen significant adoption in the industry. Early approaches focused on a pseudo-LiDAR strategy, which extracts a depth map and then back-projects this map into a 3D point-cloud; however, voxel-based approaches, such as Lift-Splat-Shoot and Fiery, took the lead due to their reduced complexity and flexibility.
Network-Based PV2BEV
- MLP-Based: These models use multilayer perceptrons (MLPs) to map PV images into BEV space; ignoring the geometric priors of calibrated cameras. This avenue was not explored deeply since the Transformer-Based methods have generally outperformed them, but notable works such as Pyramid Occupancy Networks (Shown Above) and FishingNet are notable examples.
- Transformer-Based: Transformers made
their name in the Natural Language
Processing scene and are the cornerstone of the AI boom at the end of 2022. What's amazing
is that adapting them to learn BEV representations is conceptually straightforward, and they work
really well. Not only are they an effective lifting strategy, but transformers can also be
switched out in place of backbone encoders or one of the task head(s) that the network is
predicting, which can lead to improved accuracy and reduced model complexity.
Transformer architectures may fall into two categories: sparse and dense query-based. Inspired by DETR, sparse query-based methods directly produce perception results and avoid the dense transformation of image features. These methods excel at detection tasks such as 3D object detection, but fall short at segmentation tasks. On the other hand, dense query-based methods, such as BEVFormer, methods are designed to learn BEV representations by mapping the queries into a pre-defined 3D volumetric or BEV space, which can be ported to perception tasks such as 3D object detection and segmentation; however, these models suffer in computational performance due to the dense queries which has inspired more research into efficient transformer architectures. A notable approach is Image2Map, which assumes a 1:1 relationship between vertical scanlines of an image and the camera rays in the BEV space, which avoids the dense query problem.
Benchmarking BEV for Perception

Datasets offering diverse scenes for training and testing are crucial for researchers to benchmark BEV models. Three of the big names are:
- KITTI: A well-known benchmark with over 7,500 samples for testing with both 2D and 3D annotations.
- nuScenes: A massive dataset with 1,000 scenes, each lasting 20 seconds, offering a 360-degree field of view.
- Waymo Open Dataset (WOD): One of the largest autonomous driving datasets with nearly 800 sequences for training.
Other datasets worth mentioning include Argoverse, H3D, and Lyft L5, which are also popular for testing BEV models.
For perception evaluation metrics, the most commonly used criterion for BEV Detection is Average Precision (AP) and the mean Average Precision (mAP) over different classes or difficulty levels. For BEV Segmentation, Intersection over Union (IoU) is used for each class and mIoU over all classes are frequently used as the metrics.
Final Thoughts
Following the timeline of the evolution of autonomous driving, we can see a clear pattern
of classical rule-based techniques being replaced with network-based approaches. New research
explores how to
expand these networks to handle the entire end-to-end, from sensor input to planning of the automated
vehicle.
What does this mean for the automotive industry and software engineering teams that
have been developing perception, localization, and planning pipelines using rule-based
techniques?
I don't have a magic crystal ball, but after being on the field as an ADAS engineer for a few years, I
can give an informed perspective.
Modern network-based
architectures will continue to grow and
dominate cutting-edge autonomous systems that we see from companies like Wayve and Waymo, but traditional
algorithms still play a vital role
due to their
compatibility & efficiency in resource-constrained systems that the majority of current cars use. It's
likely that the roadmap to end-to-end adoption will be a slow burn that will naturally build as
vehicle hardware architectures evolve. Organizational shifts will also need time to transition from
rule-based development to network-based applications, which will drive upskill from traditional
software development
methodologies to the AI centric data-driven paradigm.
In my view, the real challenge lies in addressing the external factors. Regulatory approval for
autonomous driving has evolved from minimal oversight during early experimental testing to rigorous
safety and explainability requirements, now focusing on functional safety, liability, and cybersecurity.
As AV technology matures, international regulations emphasize level-specific testing, data-driven
validation, and public trust to ensure safe deployment.
Perhaps the most important factor is the customer. Autonomous driving is
ultimately a feature of the vehicle, not the sole purpose of its design. While the allure of
cutting-edge, fully autonomous systems is undeniable, automakers must strike a balance between
technological advancements and the practical benefits they deliver to the consumer. It’s essential for
automakers to focus on features that provide real value to drivers, rather than forcing innovations that
may not align with consumer desires.