
Multi-Task Learning and Deployment
Deep learning was a fascinating but elusive field to me during my time as a masters student.
By the time I graduated in 2020, I was too busy breaking into the software development scene and landing
my first job to explore its depths. Back then, landing a machine engineering role was rare, with an
intimidatingly high bar for entry. It seemed like a moonshot for someone with my
experience, so I put it on hold.
Fast forward to today, I get to work on cutting-edge perception-centered features in production
autonomous driving applications, and my software engineering skills have been accelerating. With a
clearer vision of the engineering and cross-team workflows, I figured it was time to dive in.
Multi-Task Learning in Action
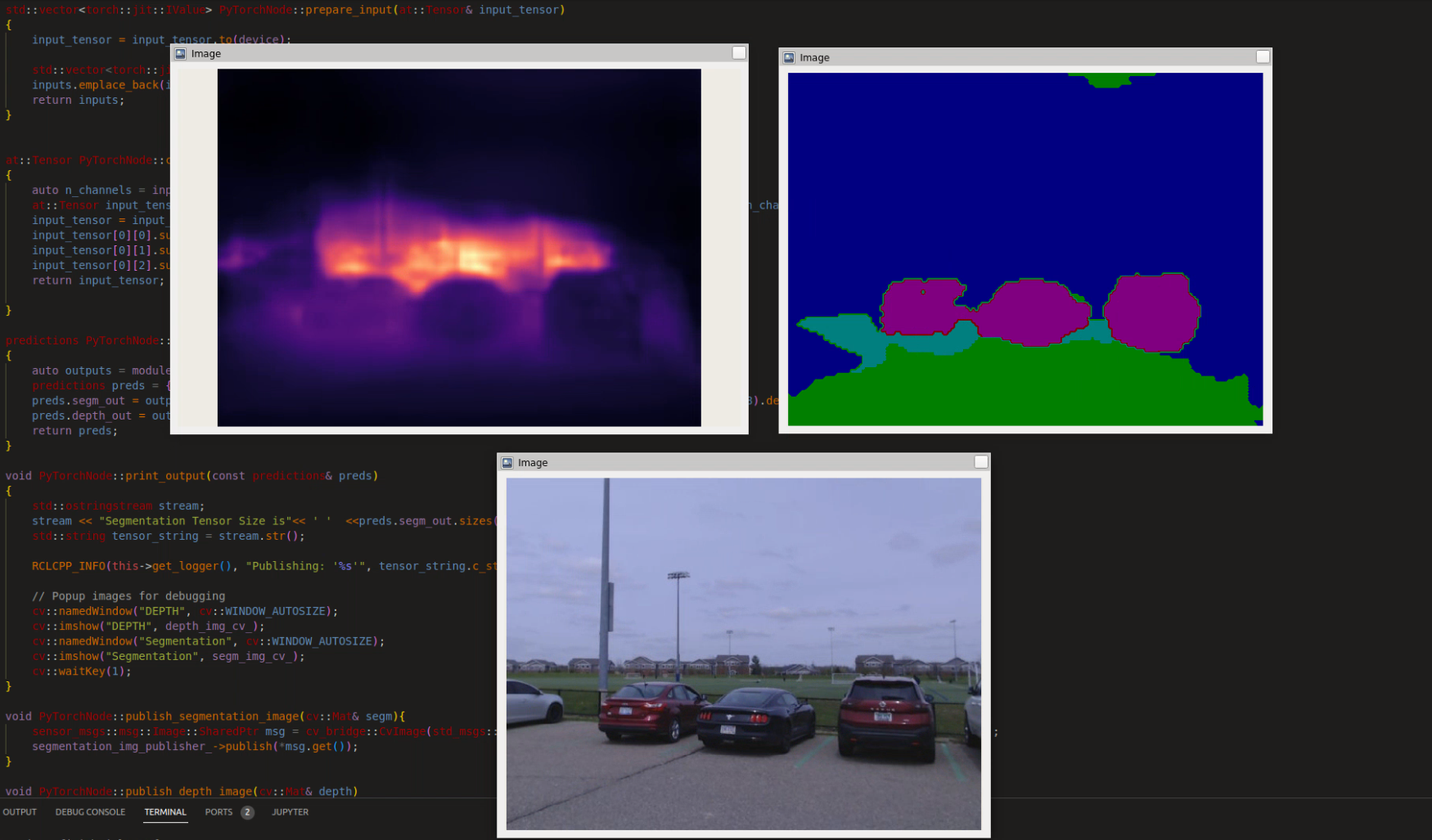
The video above illustrates depth and semantic segmentation inferences from a Hydranet model deployed in
ROS2 middleware. The image stream is vehicle sensor data that my friends and I collected while driving
around my university campus.
Coined by Tesla, the term Hydranet is single deep learning model that is capable
of
inferencing multiple tasks, as opposed to the convention of deploying models that perform a single task,
which would place needless memory constraints on the hardware. Hydranets have been an integral
optimization tool
in autonomous driving applications due to this efficiency.
Setting Learning Goals
Deep learning is an ever-evolving field, making it challenging to know where to begin and how to
effectively advance towards cutting-edge techniques.
In addition, deploying and integrating these models can be particularly complex in robotics, where high
throughput
and real-time performance are essential.
Aiming for a balance between research and deployment, I set the following objectives:
- Develop the ability to understand and critically assess state-of-the-art deep learning papers.
- Gain hands-on experience in building and training deep learning models.
- Learn to deploy machine learning models within robotic systems.
Deep Learning Path
Fundamentals
Having just graduated with my second engineering degree, I wasn't too keen on shelling out more cash for
education. I chose the
cost-effective, scenic route picking up the basics.
I started with a miniseries on Deep Learning
Fundamentals, which taught me the basics of deep learning. I then graduated to fastai's Practical Deep
Learning
for Coders. This course did wonders for me as it gave me hands-on experience on a breadth
of machine learning avenues,
from classical concepts such Random Forests, to Convolutional Neural
Networks and Natural Language Processing using Transformers.
My last venture on fundamentals was Deep Lizard's PyTorch-Python Deep
Learning API, which further drove down on my practical experience, but with a tailored focus to
the popular PyTorch framework.
Automated Driving
My next move was to specialize in deep learning for autonomous driving, I enrolled in Jeremy Cohen's Think Autonomous courses for Hydranets and Neural Net Optimization. These courses were very helpful in getting an intuitive understanding more advanced concepts and techniques, some of which we will discuss in the next sections.
Hydranet Architecture
Simply put, a Hydranet, officially termed as Multi-Task Learning, is a deep learning model that is designed and trained to inference multiple outputs. They're popular due to their efficiency and low latency, as they allow multiple tasks to share a common feature extraction backbone, reducing the overall computational load. This shared representation not only conserves resources but often improves the performance of each task by leveraging the complementary nature of shared features.
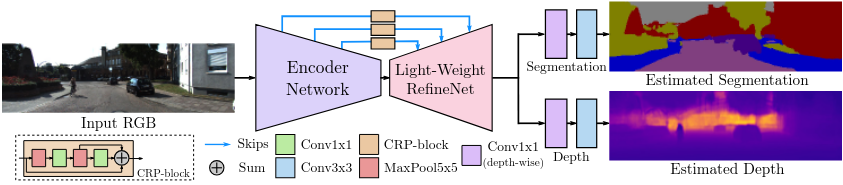
The Hydranet architecture we studied was from this paper. Much like the well-known U-Net, this model follows an encoder-decoder architecture. The encoder takes in a single image and reduces the spatial dimensions while increasing feature channels, and the decoder restores spatial dimensions with skip connections from the encoder. This enables the model to retain spatial features while leveraging the encoder’s feature extraction power.
For real-time applications, the authors of the paper focused on efficiency, using Mobilenet V2 as the encoder and a lightweight RefineNet as the decoder. They authors also incorporated techniques like depthwise separable convolutions to reduce the number of parameters and floating-point operations of the model during inference
Considerations for Multi-Task Learning
We looked at a thin slice of Multi-Task Learning, but I think it's worth sharing these considerations.
Loss Weighting
A loss function is a mathematical function that measures the difference between the model's predictions and the ground truth labels, which are applied to the model during the training phase. So how do we handle multiple loss functions from different tasks?
Uncertainty weighting is a early approach that allows the model to capture the complex interplay between tasks and balance performance across them by weighting each loss function by the uncertainty of each task. These uncertainties are parameters that are aim to balance the learning of the model.
Another approach is GradNorm, which is a gradient-based method that dynamically adjusts the learning rate of each task based on its relative importance. By normalizing the gradients of each task, GradNorm ensures that the model is updated in a way that is proportional to the importance of each task. This helps to balance performance across tasks and improve overall performance.
Meta-Learning Task Weighting is a method that uses meta-learning to automatically adjust the weights of each task based on the performance of the model. This approach involves training a meta-model to predict the optimal weights for each task, given the current performance of the model. By using the meta-model to adjust the weights of each task, this approach can improve overall performance and balance performance across tasks.
Task Dependence
Deciding which tasks to learn is a crucial consideration. Some tasks may be inherently related, where learning one task can benefit the learning of another, and improve the model's accuracy, while certain pairings of tasks may negatively impact model learning and convergence.
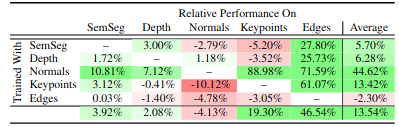
The snippet above comes from this paper. Here the authors highlight results from pairing tasks. We see that including the normals task gave a generous boost in performance, whereas synergies between semantic and depth did not provide much benefit. You can actually improve the performance of the model by including extra tasks such as normals, even if they are not relevant to the task at hand.
Model Deployment
ROS2 (Robot Operating System 2) is an open-source middleware that acts as a communication layer between different processes and hardware devices, enabling efficient data exchange while providing a modular design.
When it comes to deploying deep learning models, the process typically involves converting the model from a development environment to a production-ready format that can run efficiently in real-time applications. In my case, I wanted to integrate the Hydranet model into ROS2, aiming to learn both ROS2 and deep learning together. Initially, I used JIT to trace the model and the Libtorch C++ API, to handle, import and inferencing in ROS2. This allowed me to take a model from eager mode and deploy it into production mode.
However, there are more official ways to deploy machine learning models in ROS2 or similar systems. For instance, ONNX (Open Neural Network Exchange) allows for easy model export and cross-platform deployment. ONNX models can be used across frameworks and hardware, ensuring compatibility with performance-optimized libraries.
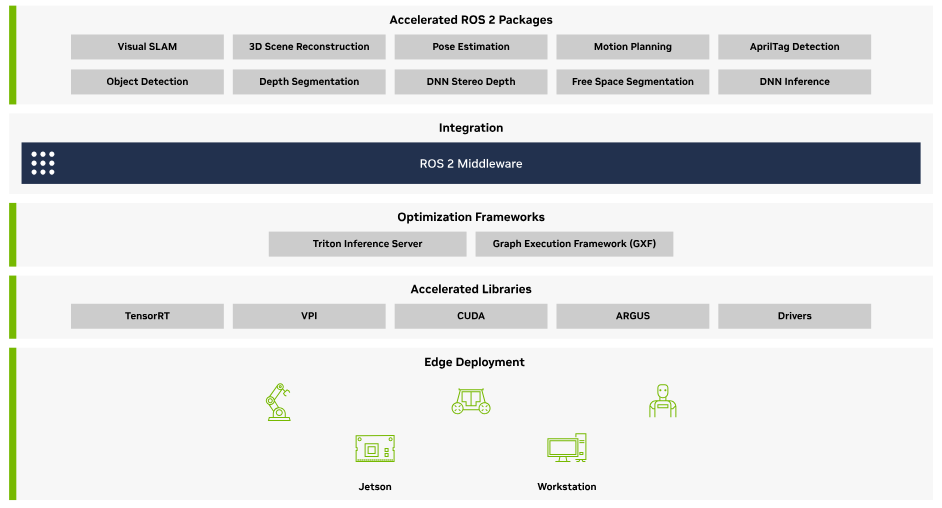
In the robotic ecosystem, NVIDIA offers Isaac ROS for seamless integration of models into ROS nodes with hardware acceleration. This allows for faster inference and better performance in tasks such as object detection, segmentation, and other autonomous tasks within the robotics system. Using these tools, you can not only deploy your models but also benefit from hardware-accelerated inferencing, making the integration process much more efficient and suitable for real-time applications.
Solutions exist outside of robotic middleware for edge or on-premise systems. Specialized stacks like Intel's OpenVINO or NVIDIA's DeepStream can be employed for applications such as video surveillance systems.
Reflection on Learning Goals
Reflecting on my learning goals, it’s clear how each one contributed to my growth, not just as an engineer but as a learner. The ability to critically assess state-of-the-art deep learning papers seemed daunting at first, but over time, I got the hang of it and it became a rewarding challenge. Learning to navigate the complex language of academic research has deepened my understanding of the field and allowed me to implement cutting-edge ideas into practical systems.
Gaining hands-on experience with Multi-Task Learning to build and train deep learning models was both fulfilling and humbling. Each project was an opportunity to test my skills, learn from mistakes, and celebrate the small victories that came with a functioning model.
Deploying the Hydranet model into ROS systems was where everything came together. It allowed me to gain hands-on experience from understanding model architectures to integrating them into real-world environments and understanding the landscape of model deployment.